InnoDB 스토리지 엔진
InnoDB는 MySQL에서 주로 사용되는 스토리지 엔진의 한 종류입니다.
InnoDB는 레코드기반 잠금을통해 높은 동시성 처리가 가능하고, 성능이 안정적인것으로 알려져 있습니다.
아래는 InnoDB 스토리지 엔진의 아키텍처입니다.
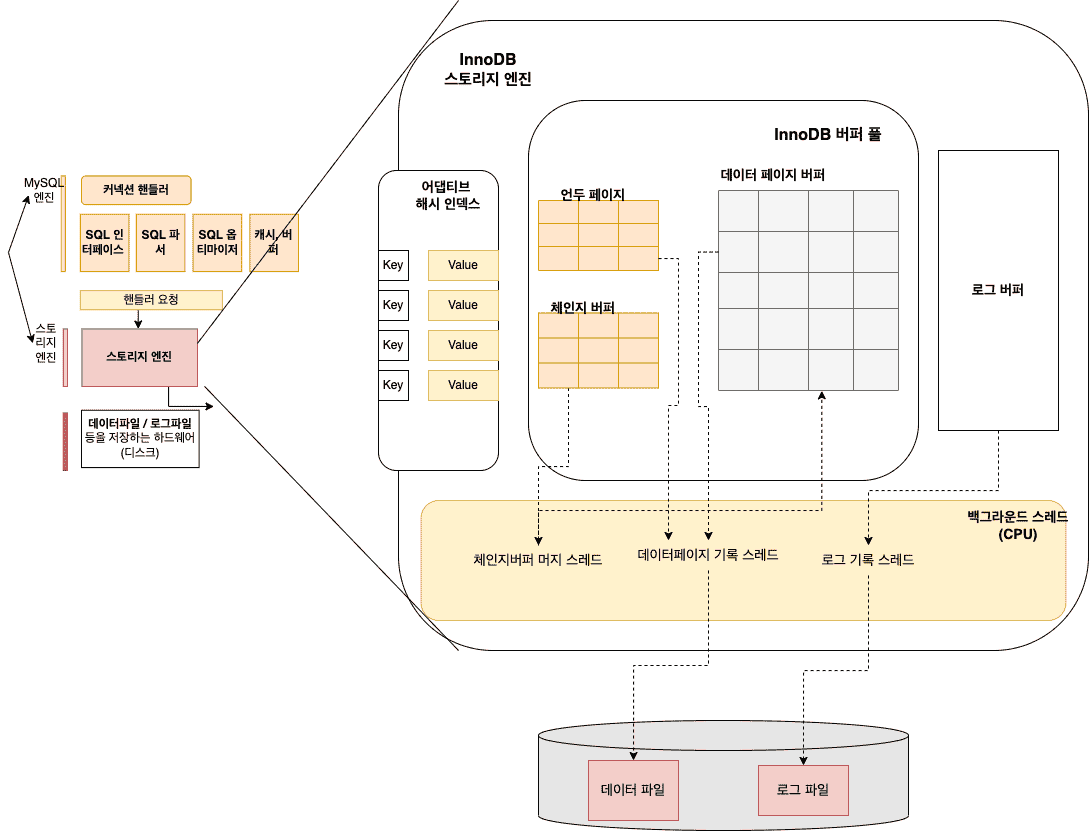
프라이머리 키에 의한 클러스터링
Inno DB에서는 Table은 Primary Key를 기준으로 클러스터링되어 저장됩니다. 이는 물리적으로 Primary키가 연속된 순서로 저장된다는 의미입니다. ( 세컨더리 인덱스의 경우 Primary Key를 논리적인 주소로 사용해 이를 참조하는 방법으로 사용합니다.)
이를 통해 PK를 이용한 Range Scan이 상당히 빨라지며, 쿼리 실행계획에서도 다른 인덱스보다 PK의 우선순위를 높게 설정합니다.
외래 키 지원
스토리지 엔진 레벨에서 지원하는 외래 키를 제공합니다.
외래키는 연관 테이블에 락을 걸고, 이로 인해 데드락이 발생하는 경우가 있어 성능 문제가 발생할 수 있습니다.
외래 키가 복잡하게 얽힌 경우 여러 테이블로 EX Lock**확인필요이 전파되어 성능저하를 불러일으킵니다.
MVCC : Multi Version Concurrency Control
레코드 레벨 트랜잭션을 지원하기 위해 DBMS가 제공하는 기능이며, 이 기능을 통해 잠금을 사용하지 않는 일관적읽기를 사용할 수 있습니다.
Buffer Pool: 쿼리 실행결과 레코드를 가지고있는 데이터 영역
Undo Log: 데이터 변경 시,변경 이전의 커밋된 레코드를 복제해놓는 곳. 이를 참조해 Transaction 취소 시 Rollback을 수행할 수 있습니다.
Read-Uncommited → buffer pool의 데이터 그대로 읽음
Read-Committed 이상의 격리수준→ Undo Log의 데이터를 읽음
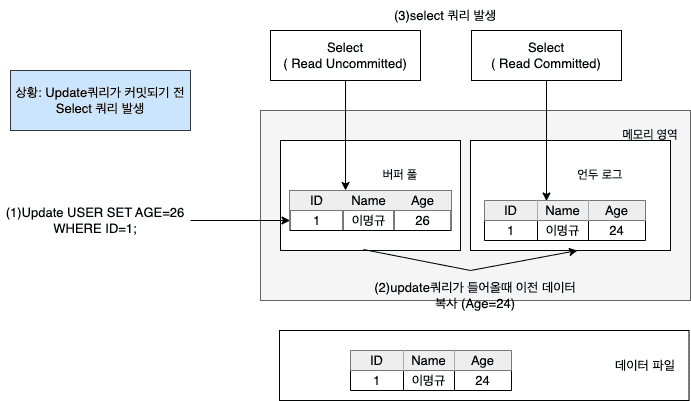
잠금 없는 일관된 읽기를 제공합니다. MVCC와 같은 이야기. 순수한 읽기 작업에서 Lock에 의한 대기 없이 데이터를 읽어도 데이터의 일관성이 보장됩니다.
1) Insert쿼리 커밋 이후 Age를 변경하는 Update 쿼리를 작성
2) Insert쿼리는 커밋되었지만 Update age=26은 커밋되지 않아 언두로그에 변경 이전 커밋된 데이터가 남아있음
- 읽기 격리수준에따라 다른 버전의 데이터를 읽어 락을 적용하지 않고도 격리수준 보장 가능
3-1) Read-Committed 이상의 엄격한 격리수준에서는 Undo Log에 있는 커밋된 데이터를 읽음
3-2) Read-UnCommitted 격리수준에서는 커밋되지 않은 버퍼 풀의 데이터를 읽음
자동 데드락 감지
MySQL에서는 데드락을 탐지하기 위해 잠금 대기 목록을 그래프 형태로 관리합니다. 두 개 이상의 스레드가 락을 획득하는 과정에서 데드락에 빠졌을 때, 부하를 줄이기 위해 언두로그가 적은 순으로 트랜잭션을 강제종료합니다.
자동 데드락 감지 기능에는 몇가지 한계점이 존재하고, 이를 극복하기 위한 방법들이 있습니다.
테이블 레벨 잠금
InnoDB엔진의 상위 레이어인 MySQL엔진에서 관리하는 테이블 잠금은 스토리지 엔진에서 확인할 수 없습니다. 리를 위해 innodb_table_locks 변수를 활성화하면 테이블 레벨 잠금도 확인할 수 있습니다.
잠금 목록에 대한 잠금
백그라운드 스레드가 잠금 목록에 접근해 데드락을 탐지하기 위해서는 잠금 목록도 락을 걸어준 후 접근해야 합니다. 이 과정에서 다른 스레드는 잠금목록에 접근하지 못해 병목현상이 생기고, 이는 서비스에 악영향을 미칩니다.
이를 위해 innodb_deadlock_detect 설정을 OFF로 지정하면 데드락 감지는 더이상 발생하지 않고, innodb_wait_timeout변수를 적절히 설정하면 일정 시간 이후에 자동으로 요청 실패 후 에러메시지를 반환합니다.
InnoDB 버퍼 풀
디스크 데이터파일, 인덱스 정보 등을 메모리에 캐시해두는 공간입니다.
DML을 메모리상에서 캐시하면 디스크의 Random IO 횟수를 대폭 줄여 성능이 향상됩니다.
할당 크기 조절
버퍼 풀을 통한 캐시 영역이 늘어날수록 성능이 일정부분 향상되지만, MySQL 5.7 이상 버전부터 버퍼 풀을 실행중 동적으로 확장할 수 있게 되었습니다.
버퍼 풀을 줄이는것은 시스템 영향도가 크므로, 50%에서 시작해 점점 늘려가며 최적점을 찾는것을 권합니다.
(공식문서에서는 데이터베이스 전용 서버 기준 최대 80%까지 늘려서 사용할 수 있다고 합니다)
버퍼 풀 개수 설정
버퍼 풀 전체를 관리하는 잠금으로 인해 버퍼 풀을 하나만 사용하는것은 잠금 경합을 자주 일으키므로, 여러 개의 버퍼 풀을 생성해 잠금 경합을 분산시킬 수 있습니다.
일반적으로 버퍼 풀에 할당된 메모리 5GB당 1개정도 수준으로 설정하는것을 권장합니다 (40GB의 경우 8개)
버퍼 풀에서 관리하는 데이터 종류
- LRU 리스트 - LRU + MRU 캐시
LRU 리스트에서는 실질적인 캐싱을 담당하는 데이터/인덱스 페이지를 저장합니다.
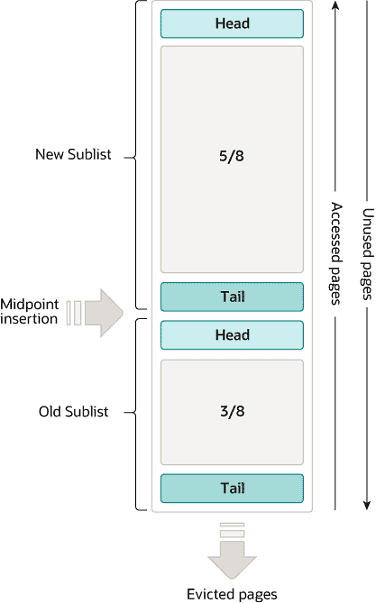
이미지 출처: https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html
5/8을 기점으로 New/Old Sublist가 존재합니다. 이들은 각각 Double Ended Linked List입니다.
아래 과정을 통해 자주 사용된 데이터를 관리합니다.
어댑티브 해시 인덱스 또는 LRU 리스트에서 Cache Hit로 버퍼 풀의 데이터를 캐싱한 경우
- 해당 데이터페이지는 New Sublist의 Head로 지정됩니다.
Cache Miss로 인해 새로운 데이터가 들어오는 경우
- 새로운 데이터 페이지는 Old Sublist의 Head로 할당됩니다.
- (read_ahead로 인해 읽힌 페이지는 이 작업을 수행하지 않습니다.)
- read_ahead란 페이지를 포함하는 extent(8~64개 페이지 그룹)를 전부 버퍼 풀에 prefetch하는 작업
캐시에 적재된 후 Age가 임계치를 넘은 경우
- 캐시에서 제거합니다 ( Eviction )
캐시 데이터를 자주 접근한 경우
- 어댑티브 해시 인덱스에 적재합니다.
2) Flush 리스트
더티페이지(디스크로 동기화되지 않은 데이터) 목록을 관리합니다. 특정 시점이 지날때마다 디스크로 플러시해 디스크와 페이지에 대한 동기화를 관리합니다.
3) Free 리스트
버퍼 풀에서 실제 데이터가 아닌 비어있는 페이지의 목록, 디스크로부터 페이지를 새로 읽어올 때 프리 리스트에 있는 페이지에 데이터를 할당합니다.
리두로그
redo log는 InnoDB 스토리지 엔진에서 사용되는 기능으로, 트랜잭션의 변경 내용을 디스크에 기록하기 전에 임시 파일에 기록합니다. 이를 통해, 데이터베이스 서버가 갑작스럽게 종료되는 경우에도 트랜잭션의 내용을 복구할 수 있습니다. 또한, redo log의 크기를 조절하여 성능을 향상시킬 수 있습니다.

이미지 출처 https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html
스토리지 엔진과 디스크상의 파일들의 동작에 대해 설명하는 그림입니다.
- 리두로그는 DB recovery작업 중, 불완전한 트랜잭션 등으로 인한 잘못된 데이터를 복구하는 데 사용됩니다.
InnoDB의 버퍼 풀은 데이터 캐싱과 쓰기 지연이라는 두 가지 용도가 있습니다.
- 리두 로그는 버퍼 풀의 쓰기지연 성능을 향상시킵니다.
버퍼 풀의 더티 페이지는 Log Buffer에서 LSN(Log Sequence Number)를 통해 관리하다가 주기적으로 체크포인트 이벤트를 발생해 로그 파일로 이를 동기화합니다.
또한 트랜잭션이 커밋될 때도 체크포인트 이벤트를 발생해 데이터를 디스크로 동기화합니다.
앞서 확인했듯 변경되지 않은 데이터는 Undo Log에 저장되어있고 변경된 데이터는 버퍼 풀에 있으니 트랜잭션은 읽기/쓰기 작업을 디스크 I/O없이 수행할 수 있습니다.
그러므로 리두 로그는 버퍼 풀이 쓰기지연 할 수 있도록 하며, 그 성능은 로그버퍼 크기에 따라 결정됩니다.
일반적으로 버퍼 풀 크기의 5~10%정도로 할당하고 점진적으로 올리는 방법을 통해 최적화합니다.
더 알아볼 내용
버퍼 풀 플러시
플러시 리스트 플러시
프리 리스트 플러시Undo Log
트랜잭션 및 격리수준을 보장하기 위해 DML 이전에 레코드 상태를 보존하는 메모리 내 저장장소입니다.
- 트랜잭션 보장: All or Nothing - 트랜잭션이 완료되지 않고 종료되면 Undo Log에 저장된 데이터로 롤백
- 격리수준 보장: 트랜잭션 도중 다른 트랜잭션이 데이터를 읽으려 할 때 격리수준에 맞게 Undo Log의 데이터를 읽도록 함
Change Buffer
인덱스가 있는 컬럼에 Update를 하거나 Insert, Delete시에는 인덱스를 수정해야하는데 이는 많은 작업을 요합니다. 추후 변경할 인덱스 페이지를 Change Buffer 메모리 영역에 저장해두고 백그라운드 스레드(Merge Thread)가 병합하도록 합니다.
해당 작업은 Unique Index에 대해서는 수행하지 않으며, 인덱스 관련 모든 작업에 수행할 수 있도록 할 수 있습니다 ( V 5.5+ ~ )
옵션 - innodb_change_buffering
all : 모든 인덱스 관련 작업에 버퍼 수행 (insert,delete, purge)
none: 모든 작업에 수행하지 않음
inserts: 삽입작업에 대한 인덱스만 버퍼링
deletes: 삭제작업(삭제에 대한 마킹)에 대한 인덱스만 버퍼링
purges: purge(완전 삭제)에 대한 인덱스만 버퍼링
어댑티브 해시 인덱스
InnoDB 스토리지 엔진에서 사용자가 자주 요청하는 데이터에 대해 자동 생성되는 자료구조.
B-Tree 인덱스도 결국 데이터 양에 따라 느려지게 되므로, 자주 읽히는 데이터 페이지의 키 값을 이용해 어댑티브 해시 인덱스를 검색해 지정된 데이터 페이지를 즉시 찾아갈 수 있습니다.
어댑티브 해시 인덱스가 큰 도움이 되는 경우
디스크의 데이터가 버퍼 풀 크기와 비슷한경우 (읽기가 많지 않은 경우)
동등 조건 검색이 많은 경우 (In 또는 ==)
일부 데이터에 대한 집중적인 참조가 있는경우
→ 비슷한 데이터에 대해 집중적인 참조
어댑티브 해시 인덱스가 크게 도움되지 않는 경우
읽기 작업이 많은 경우
Join또는 Like쿼리가 많은 경우
넓은 범위의 레코드를 읽는 경우
→ 다양한 데이터에 대한 참조
InnoDB외의 스토리지 엔진
InnoDB는 MySQL에서 가장 많이 사용되는 스토리지 엔진 중 하나입니다. 하지만 MySQL에는 InnoDB 외에도 다른 스토리지 엔진이 존재합니다.
MyISAM
MyISAM은 MySQL에서 사용되는 스토리지 엔진 중 하나입니다. MyISAM은 데이터를 인덱스 파일과 데이터 파일로 분리하여 저장합니다. 이렇게 분리함으로써, 인덱스 파일과 데이터 파일을 개별적으로 읽고 쓸 수 있어서 더 빠른 속도를 제공합니다.
MyISAM은 InnoDB와 달리 트랜잭션 처리를 지원하지 않습니다. 따라서, 트랜잭션이 필요하지 않은 읽기 작업이 많은 경우에 적합합니다. MyISAM은 SELECT 작업이 빈번한 테이블에 적합하며, FULLTEXT 검색 기능도 지원합니다.
MyISAM은 테이블 락을 사용하기 때문에, 동시에 여러 클라이언트가 데이터를 수정하려고 할 경우에는 성능이 저하될 수 있습니다. 따라서, MyISAM은 읽기 작업이 많은 웹 사이트와 같은 환경에서 적합합니다.
MyISAM은 InnoDB와 달리 트랜잭션 처리를 지원하지 않습니다. 하지만 대신 매우 빠르고, 덤프 및 복구 과정도 쉽습니다. 또한, Full-text 검색 기능도 지원합니다. MyISAM은 데이터베이스의 읽기 작업이 많은 경우에 적합합니다.
MEMORY
MEMORY 엔진은 디스크 대신 메모리에 데이터를 저장합니다. 데이터가 메모리에 저장됨으로써 빠른 속도를 제공합니다. 하지만, 데이터베이스 서버가 종료되거나 재시작될 경우에는 모든 데이터가 손실됩니다. 따라서, 단기간의 데이터 저장에 적합합니다.
Archive
Archive 엔진은 매우 빠른 INSERT 및 SELECT를 지원합니다. 하지만, 데이터 수정 및 삭제 작업이 느리고, 인덱스 기능이 없습니다. 따라서, 로그나 센서 데이터와 같은 대량의 데이터를 저장할 때 적합합니다.
CSV
CSV 엔진은 CSV 파일 형태로 데이터를 저장합니다. 따라서, 데이터의 가독성과 이식성이 용이합니다. 하지만, 인덱스 기능이 없으며, 대량의 데이터를 처리하기에는 적합하지 않습니다.
Federated
Federated 엔진은 원격 데이터베이스 서버의 테이블에 대한 연결을 지원합니다. 따라서, 여러 데이터베이스 서버에서 데이터를 읽고 쓸 수 있습니다. 하지만, 원격 서버가 다운되면 데이터 접근이 불가능합니다.
Conclusion
InnoDB는 MySQL에서 가장 많이 사용되는 스토리지 엔진 중 하나입니다. 하지만, 데이터베이스의 용도에 따라 다른 스토리지 엔진을 사용할 수 있습니다. 적절한 스토리지 엔진을 선택함으로써 더욱 효율적인 데이터베이스 운영이 가능합니다.
Reference
백은빈,이성욱 저 Real MySQL 8.0 ( http://www.yes24.com/Product/Goods/103415627 )
MySQL InnoDB 공식문서
-
innodb engine https://dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html
-
redo log https://dev.mysql.com/doc/refman/8.0/en/innodb-redo-log.html
-
buffer pool https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html
-
숙제
멀티 서버에서 선착순 기능
1)트리거
2)분산락
999명에서 서버 123이 동시에 999를 읽고 나 마지막 1000번째야 라고 요청한 상황
쿼리 수 제한?
서버1
서버2 Queue(1000 Insert Query) DB EX Lock 1002
서버3
EX - 베타락 (쓰기 쿼리를 동작시키는 “쓰레드”가 레코드에 대해 획득)
S - 쉐어락 (읽기 할 때)
선착순 1000까지 가능
(읽기)스레드 A가 레코드 1에대해 S락 획득
(읽기)스레드 B도 레코드 1에 대해 S락 획득 가능
(쓰기)스레드 C는 레코드 1에 대해 EX락 획득 가능
(쓰기)스레드 C는 레코드 1에 대해 EX락 획득
(쓰기)스레드 B는 레코드 1에 대해 EX락 획득 가능
(읽기)스레드 A가 레코드 1에대해 S락 획득 불가