UNIX에서의 파일시스템 살펴보기
Windows는 NTFS 파일시스템을 사용하고, MFT(Master File Table)을 통해 메타정보를 관리합니다.
운영체제별로 파일시스템을 구현하는 방법은 다릅니다.
아래에서는 교본에서 주로 사용되는 UNIX를 기준으로 설명합니다.
(간단한)파일시스템의 구성
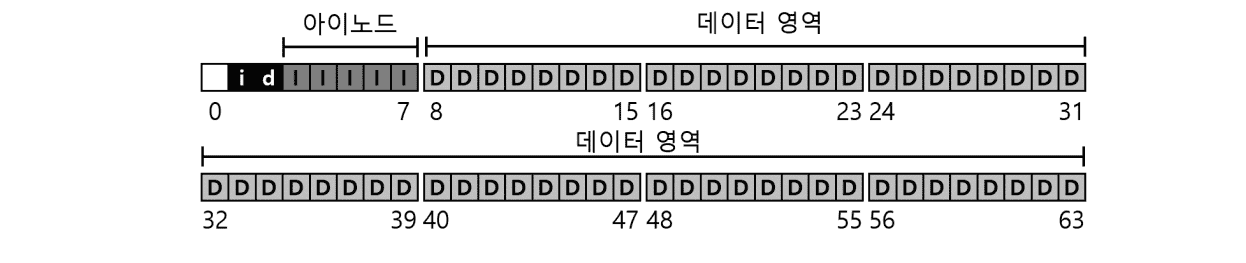
만약 운영체제를 구현해야 하고, 일정 크기의 디스크 저장장치가 존재한다면, 위와 같이 파일시스템에서 사용할 정보를 구성할 수 있습니다.
4KB의 블록이 64개 존재하는 작은 디스크에서의 파일 시스템 구성입니다.
Inode의 크기는 보통 64 ~ 256Byte 사이이므로, 4KB인 블록에는 최소 16개의 파일 정보를 저장할 수 있습니다.
슈퍼 블록(0): 파일시스템의 종류, 데이터블록, 아이노드 블록이 시작하는 위치 등 ,파일시스템의 메타정보를 저장하는 데이터 블록입니다.
비트맵 블록 (1~2): 빈 블록을 체크하는 역할을 합니다. 모든 시스템에 디스크의 빈 공간을 계산하기 위한 자료구조가 있으며, 보통은 링크드리스트로 이뤄진 빈 공간 리스트를 활용해 계산합니다.
아이노드 블록(3~7) : 파일의 메타정보를 저장하는 Inode 데이터를 저장하는 블록입니다.
데이터 블록(8~63): 데이터를 저장하는 블록으로 ,파일을 구성하는 실질적인 값을 저장하고 있습니다.
VFS(Virtural File System)
가상 파일시스템이란, 다양한 벤더의 파일시스템을 하나의 파일시스템처럼 통합해 사용할 수 있는 방법입니다.
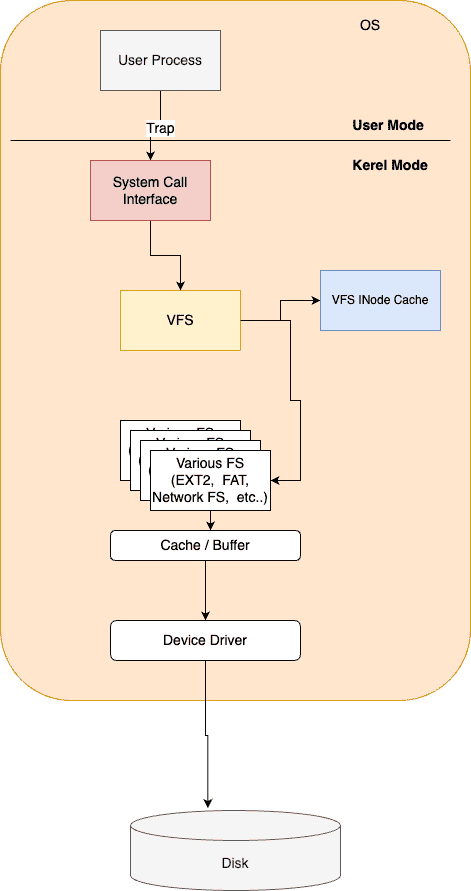
마운트
각 파일시스템의 슈퍼블록을 읽어들이는 과정입니다. 이는 운영체제가 초기화되면서 동작합니다. VFS에는 각 파일시스템의 슈퍼블록을 기록해 리스트 형태로 관리됩니다.
각 파일시스템은 /, /home, /ext 등 마운트포인트에 위치하며, 파일시스템에서 각 경로로 접근 시, 마치 하나의 파일시스템을 이용하는것처럼 해줍니다.
Inode Cache
자주 사용되는 INode에 대한 참조를 해시테이블 형태로 가지고있습니다. 이 때, 참조는 각 파일시스템의 Inode 주소를 참조합니다.
Inode (Indexed Node)
Inode란, index node의 약자로, 파일의 메타정보를 관리하고, 파일을 접근하기 쉽게 도와주는 자료구조입니다.
Inode내에서 자주 사용되는 메타정보는 아래와 같습니다.
| 고유 번호 | 파일 이름 |
|---|---|
| 그룹 | 소유자 |
| 파일모드 (user/group/other에 따른 rwx) | 생성/수정/접근 시각 |
| 파일 크기 | 파일 형식 |
| 파일 위치 (디스크 포인터) | 기타 등 |
멀티레벨 인덱스
데이터베이스 인덱스와 유사한 구조.
대용량 파일에 대한 인덱스를 유지하기 위해, 최대 3 level까지 간접 인덱스 참조를 통해 디스크 포인터를 얻어올 수 있습니다.
저장장치 가상화
앞서 살펴봤듯, 디스크와 같은 영속 저장 자원은 실린더, 섹터, 트랙 등의 물리적인 구성요소로 이루어져 있어 운영체제 또는 사용자가 접근하기 복잡합니다.
이에 디스크 드라이브 인터페이스와 운영체제는 “파일 시스템”이라는 저장장치 가상화를 통해, 사용자가 파일단위로 데이터에 접근하고 소유권을 관리할 수 있도록 했습니다.
파일
단순한 1차원 바이트 배열. 또는 단순히 연관된 데이터의 집합이라고 이야기합니다. 여기에 inode라는 파일 고유 식별번호를 바탕으로, inode 블록에서 파일의 메타정보를 관리합니다.
- 사용자가 데이터를 접근하고 보호할 수 있는 단위입니다.
- 확장자를 통해 파일 타입을 명시합니다.
- 일반적인 파일을 비롯해 디렉터리, 소켓, 파이프, 블록/캐릭터 디바이스 등, 운영체제에서 사용하는 객체는 대부분 파일로 관리합니다.
디렉터리
파일과 마찬가지로 inode, 이름을 갖습니다. 하지만 디렉터리에는 ( inode, 파일/디렉터리 명 )으로 이뤄진 쌍을 가지고 있습니다.
- 파일의 일종입니다.
- 이는 파일 시스템이 계층형 구조를 만들 수 있도록 합니다.
- 또한, 단일레벨 파일 시스템에서 발생했던 이름 중복 문제를 완화합니다.
디스크 저장공간 관리
저장공간을 할당하는 방법
1) 연속할당 방법
파일을 디스크의 연속적인 공간에 저장하는 기법입니다.
장점)
이 방법은 파일의 데이터가 연속적으로 저장되어 있어, 순차접근 및 직접 접근 속도가 빠르다는 장점이 있습니다.
단점)
그러나 메모리 연속할당에서도 공부했듯, 자료를 공간에 연속적으로 할당하게 되면, 외부 단편화 문제가 발생하며, 이는 Compaction등을 통해 해결해야 합니다.
또한, 파일이 커질때마다 파일 위치를 재배열해야 하는 큰 단점이 존재합니다.
2) 불연속 할당 방법 (Linked Allocation)
블록이 다음 블록의 주소를 저장하는, 링크드 리스트 형식으로 데이터를 저장하는 기법입니다.
이는 Windows하위버전이나 MS-DOS에서 사용되는 파일 시스템인 FAT(File Allocation Table) 파일시스템에서 사용되었습니다.
장점)
외부 단편화도 존재하지 않고, 파일이 커져도 공간을 재배열하거나 압축해야할 필요가 없습니다. 즉, 앞선 연속 할당기법의 단점들을 모두 해결하면서, 순차접근 성능까지 보장됩니다.
단점)
다음 블록 주소를 저장해야합니다. 이는 디스크 크기가 커질수록, 주소의 크기도 커지므로 공간 낭비가 생깁니다.
직접접근성능이 현저히 떨어집니다. 특정 위치의 파일에 접근하기 위해 순차적으로 링크를 탐색해야 합니다.
3) 인덱스 할당 방법 (Indexed Allocation)
Index Block을 만들어, 파일의 인덱스 정보나 메타정보를 관리합니다.
이는 UNIX에서 사용되며, 아래에서 더 자세히 살펴보겠습니다.
장점) 순차접근과 직접접근에 일정 수준 이상의 성능을 보장합니다.
단점) 인덱스 블록을 유지하기 위해 저장공간을 사용해야 합니다.
파일 크기가 작으면 인덱스 블록이 낭비되고, 파일 크기가 너무 크면 인덱스
빈 공간을 체크하는 방법
앞선 간단한 파일시스템에서는 빈 공간을 체크하기 위해 비트맵을 사용했지만, 디스크 공간을 관리하기 위한 방법은 여러가지가 존재하고, 각각의 장단점이 있습니다.
Bit Masking
비트마스킹 블록을 사용해**,** 사용중이라면 1, 아니면 0을 저장해 파일 할당정보를 표시합니다.
이 정보를 확인하기 위해 매번 디스크에 접근할 수 없으므로 메모리에 상주시켜야 하는데, 대용량 저장장치의 경우 마스킹해야하는 범위가 넓어 마스킹 블록도 여러개를 사용해야 합니다.
2TB크기를 갖는 저장장치에 대해, 필요한 마스킹 블록 영역의 크기를 계산해보면, (블록 크기 4KB로 가정)
2TB / 4KB = 대략 5억, 5억 bit = 최소 60MB 이상의 공간이 메모리에 상주해야 합니다.
Linked List / Grouping
저장공간 할당과 마찬가지로, 빈 공간 역시 Linked List자료구조를 통해 관리할 수 있습니다.
Grouping: 직접접근 성능이 느리다는 단점을 보완하기 위해, N개의 블록을 하나의 그룹으로 묶어, 이 그룹을 Linked List로 연결해 사용할 수 있습니다.
Counting
첫 번째 빈 공간주소와 연속된 빈 공간의 수를 저장하는 Table을 저장합니다.
외부 단편화가 발생하지는 않지만, 아래와 같은 최악의 경우, Allocation Table공간의 크기가 과도하게 커질 수 있습니다.
빈 공간이 한개씩만 존재하는 Allocation Table
| Block Address | Empty Size |
|---|---|
| 0x00003 | 1 |
| 0x0001D | 1 |
| 0x0002A | 2 |
| 0x0003F | 1 |
| 0x00052 | 2 |
Reference
OSTEP: Operating Systems: Three Easy Pieces
[HPC Lab. KOREATECH, OS Lecture](https://www.youtube.com/watch?v=es3WGii_7mc&list=PLBrGAFAIyf5rby7QylRc6JxU5lzQ9c4tN)